LXMERT is a large-scale transformer model designed for learning joint representations of visual and textual data. It focuses on tasks that require reasoning over both images and language, such as Visual Question Answering (VQA) and image captioning. The model integrates a language encoder, an object relationship encoder, and a cross-modality encoder to effectively align and fuse multimodal information.
Key Features
Combines vision and language using a cross-modality transformer architecture
Trained on large-scale datasets for tasks like VQA, image-text matching, and captioning
Incorporates separate encoders for language and object-based visual inputs
Enables strong performance in multimodal benchmarks
Open-source implementation with pretrained models and evaluation scripts
.png)
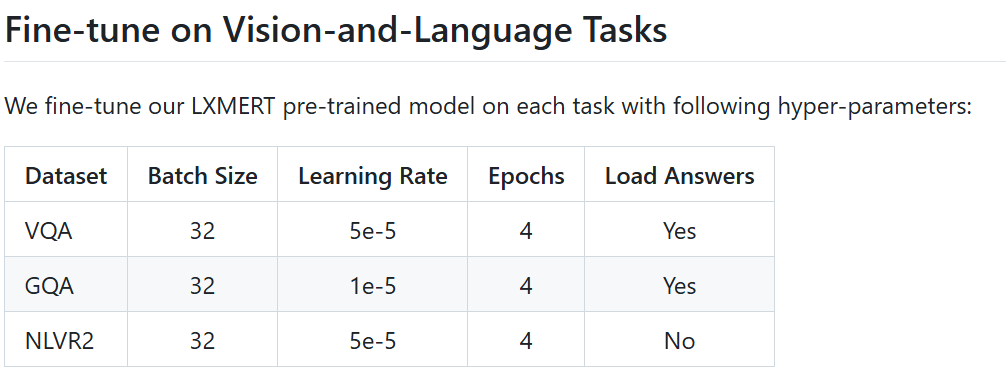

.png)
.png)
.png)
.png)

